ELK,一般被称作为日志分析系统,三款开源产品名称的首字母集合。
ElasticSerach 是一个基于Lucene之上实现的一个分布式搜索引擎,同时还提供了存储功能。
Logstash 主要用于日志的过滤、修改、收集等功能,支持大量的数据获取方式。
一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 主要用于将上诉两者通过http协议良好的展示给用户,以便用户使用。
Elasticserach和Logstash运行,依赖于java环境当中。
什么情况下需要使用到ELK。
一般我们需要进行日志分析是,直接在日志文件中 grep、awk 就可以获得自己想要的信息,但如果在规模较大的场景中,我们就需要在每一台主机上进行grep、awk等,是不是太麻烦了?就算写个脚本是否也需要对所有结果又进行整理一下,这样效率也就太低了,因此就会使用到今天讲的主角ELK,我们在分析日志直接在一台主机上搜索自己想要的信息,并且还是通过web端访问的。比上面所说的方法就要方便很多了吧。
接着我们示例一下他的部署方法
这里只准备了2台centos7的主机就不做太复杂的架构了,一台安装logstash+httpd,复杂收集HTTP日志并发往另一台主机提供的elsticsearch上。另外一台主机就安装elasticsearch+kibana。
可直接下载官网提供的RPM包,刚才去看3个包接近150M,然而速度几KB,而后果断放弃了,找到了马哥提供的RPM包,就直接下马哥的RPM包好了。
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel #下载openjdk
yum install elasticsearch-1.7.2.noarch.rpm #安装elasticsearch
tar xf kibana-4.1.2-linux-x64.tar.gz #解压kibana,kibana下载是一个压缩包
编辑配置文件。这里对elasticsearch集群做下说明,正常使用中elasticsearch应该作为集群存在,数据量过大他自身负载均衡读写也提供了存储功能,如果他挂了所有数据都丢了,你能接受吗? 要部署集群也很简单,把配置文件里面的集群名定义为一样就行了,他们会自行通过tcp的9300端口进行通讯,集群所需要的健康状态检测,选举主节点、某节点down了自动按照存储策略补齐等等,他们都会自动进行。
[root@localhost ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@localhost ~]# grep ‘^[^#]’ /etc/elasticsearch/elasticsearch.yml
cluster.name: myes
node.name: “node1”
这里只添加了此两项,其他选项还有很多,例如记录的日志分为几份存储,每一份又存储多少份,按要求自行修改即可。
[root@localhost ~]# systemctl start elasticsearch #启动服务
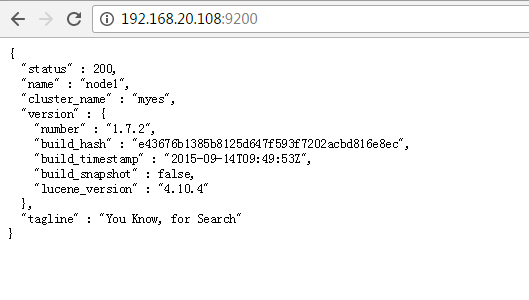
确认服务启动OK , 9200位elsticsear提供http监听的端口,9300为集群通讯端口,另外其实可以下载bigdesk-latest此插件,使用elasticsearch安装是自带的程序plugin直接安装,就可以很直观看到整个集群的状态。
[root@localhost ~]# /usr/share/elasticsearch/bin/plugin -i bigdesk -u file:///root/bigdesk-latest.zip #安装bigdesk插件
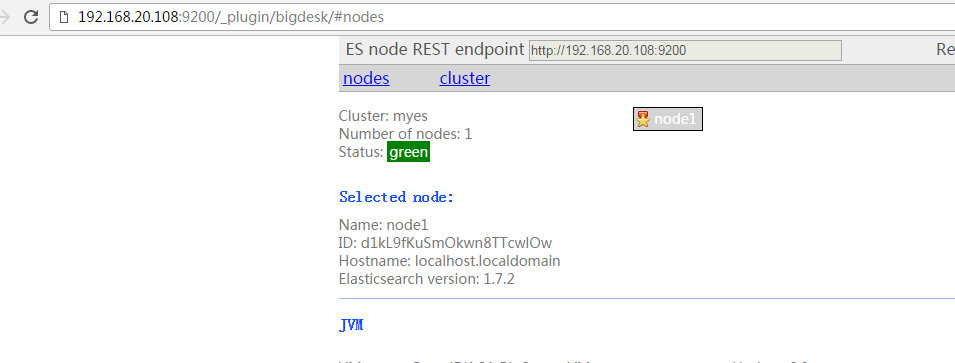
是不是可以更直观看到节点信息了~
接着我们去安装另一台主机上的http和logstash
[root@localhost ~]# yum -y install httpd logstash-1.5.4-1.noarch.rpm java-1.8.0-openjdk
export JAVACMD=`which java` #配置java环境时带上此项,否则要报错
[root@localhost ~]# vim /etc/logstash/conf.d/test.conf
[root@localhost ~]# cat /etc/logstash/conf.d/test.conf
input {
file {
path => “/var/log/httpd/access_log”
}
}
filter {
grok{
match => {“message” => “%{COMBINEDAPACHELOG}”}
}
}
output {
elasticsearch {
cluster => “myes”
index =>”logstash-apachelog”
}
}
编辑配置文件,添加以上内容
input表示从哪里输入,这里指明的是文件,还有其他很多参数,详情看官方文档
filter 表示过滤,使用grok模块过滤,下面指明将收到的文件以哪种方式拆分,具体在/opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-0.3.0/ 此目录下提供了很多模板,可自行拿来直接调用
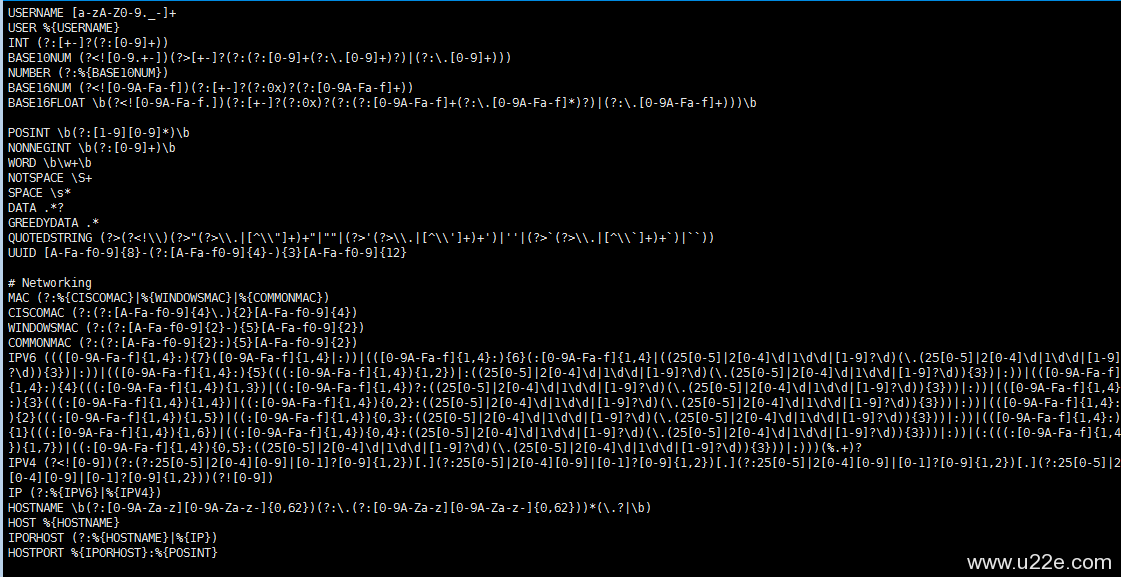
这里我打开了一个名为grok-partterns 的文件 大致可以看出第一段可以理解为为后面匹配到的内容命名,我们要使用它直接调用即可,后面的为正则表达式的具体匹配规则。
output输出指令,输出到elasticsearch,cluster指明集群名称,index代表把输出过去的内容以什么名称创建索引。
[root@localhost patterns]# logstash -f /etc/logstash/conf.d/test.conf –configtest #测试配置文件语法
Configuration OK
接着我们回到第一台主机去安装kibana,解压kibana
[root@localhost kibana-4.1.2-linux-x64]# grep ‘^[^#]’ config/kibana.yml
port: 5601
host: “0.0.0.0”
elasticsearch_url: “http://localhost:9200”
elasticsearch_preserve_host: true
kibana_index: “.kibana”
default_app_id: “discover”
request_timeout: 300000
shard_timeout: 0
verify_ssl: true
bundled_plugin_ids:
– plugins/dashboard/index
– plugins/discover/index
– plugins/doc/index
– plugins/kibana/index
– plugins/markdown_vis/index
– plugins/metric_vis/index
– plugins/settings/index
– plugins/table_vis/index
– plugins/vis_types/index
– plugins/visualize/index
特别注意上面第三个选项,是否指的是elasticsearch,这里我是同一台主机,所以无须修改,直接启动即可
[root@localhost kibana-4.1.2-linux-x64]# bin/kibana -l /dev/null &
-l 指明日志记录位置
& 后台运行
接着就可以访问本机的5601端口了
[root@localhost patterns]# systemctl start httpd
[root@localhost patterns]# service logstash start
启动logstash,可以看到启动后是监听在9300上的,意味着自己本身也是一elasticsearch集群身份于elasticsearch通讯。
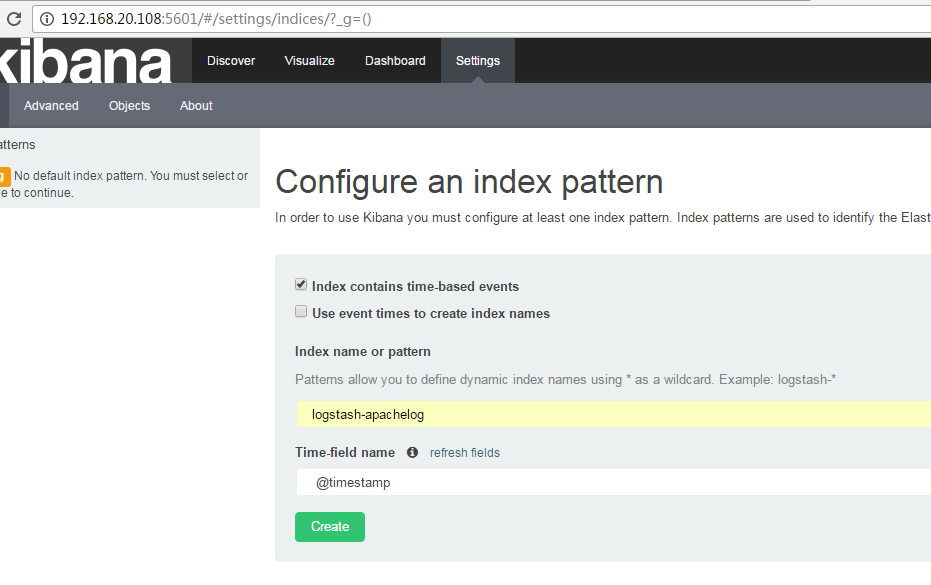
接着打开kibana主页,记得是5601端口,接着创建默认显示的索引名,就可以了

可以看到数据了,但是这里出了一个小问题,刚刚登陆进去提示没数据,我刷了几下网页过后发现还是没有,日期选择成一周,就有数据了,才发现虚拟机的时间快了一天。。。
另外在实际应用当中不用该让agent端直接往elasticsearch发送日志,需要加个server端负责统一接受client日志,再由server端统一过滤后在发送。甚至还需要在client和server端加一个队列。简单的部署就到这里吧
https://kibana.logstash.es/content/ 另外提供一个ELK官方的中文指南,以便日后真正需要用到时查询


